Features
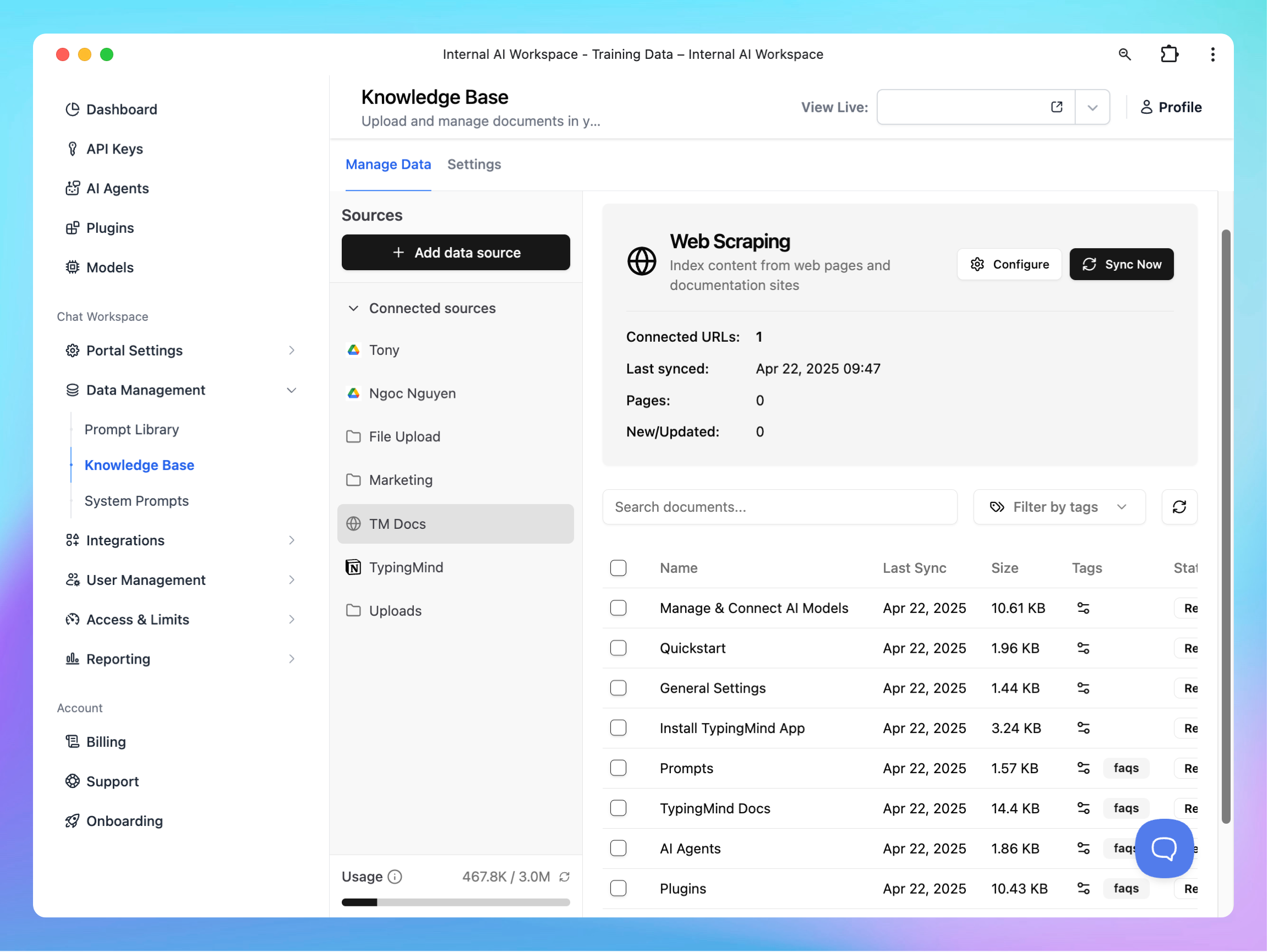
Connect Knowledge Base
Connect your knowledge base to TypingMind
ChatGPT and Large Language Models (LLMs) like Anthropic Claude and Gemini are powerful tools for brainstorming ideas, creating content, generating images, and enhancing daily workflows.
However, they have a limitation: LLMs perform best with their knowledge base / training data only.
They can't provide specific insights into your unique business needs - like detailed sales reports or tailored marketing strategies - without the access to your domain-specific knowledge base.
TypingMind can help you fill in that gap by allowing you to connect your own knowledge base to ChatGPT and LLMs easily!
Why Connect Your Knowledge Base to TypingMind?
TypingMind provides you with:
- Connect knowledge from various sources: PDF, TXT, XLSX, Notion, Intercom, Web Scrape etc.
- Keep your data fresh and updated with a single click.
- Train multiple AI models, such as GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro with your custom data.
- Ensure data security and privacy.
- Start effortlessly with no coding required.
What can you do with TypingMind Knowledge Base system?
1. Connect data from multiple sources
You can link data from various places, such as uploaded documents, Notion, Google Drive, GitHub. etc.
This keeps all your important information in one place and easy to access.
2. Use RAG to boost AI capabilities
With Retrieval-Augmented Generation (RAG), your AI model can fetch the most relevant information from the Knowledge Base to provide more accurate and helpful answers.
Learn more: How Knowledge Base works
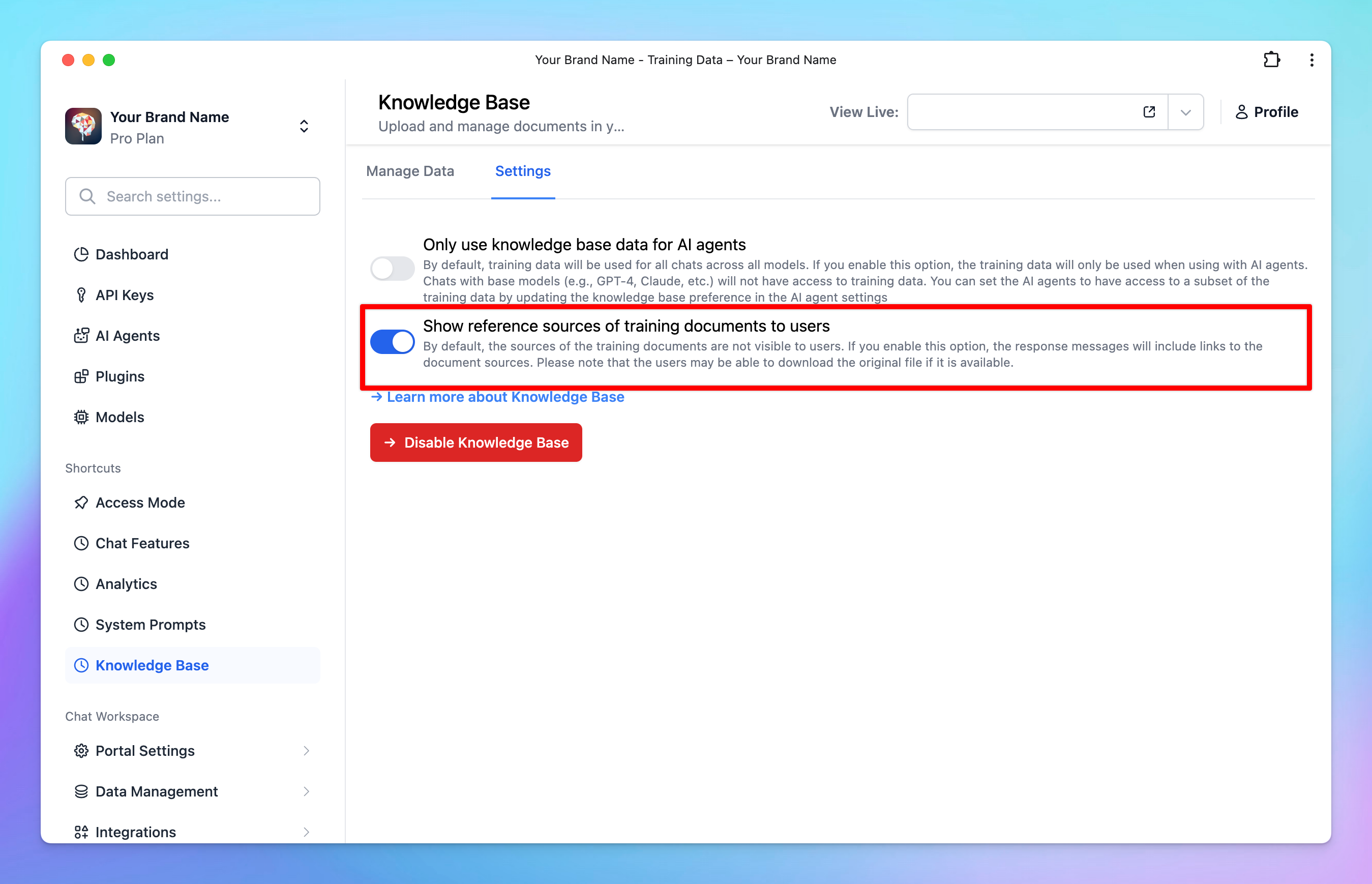
3. Cite sources with links
When you enable “Show reference sources of training documents to users”, the system can cite sources with clickable links. This helps users to trace the origin of the AI’s responses to provide more transparency and reliability in the generated responses.
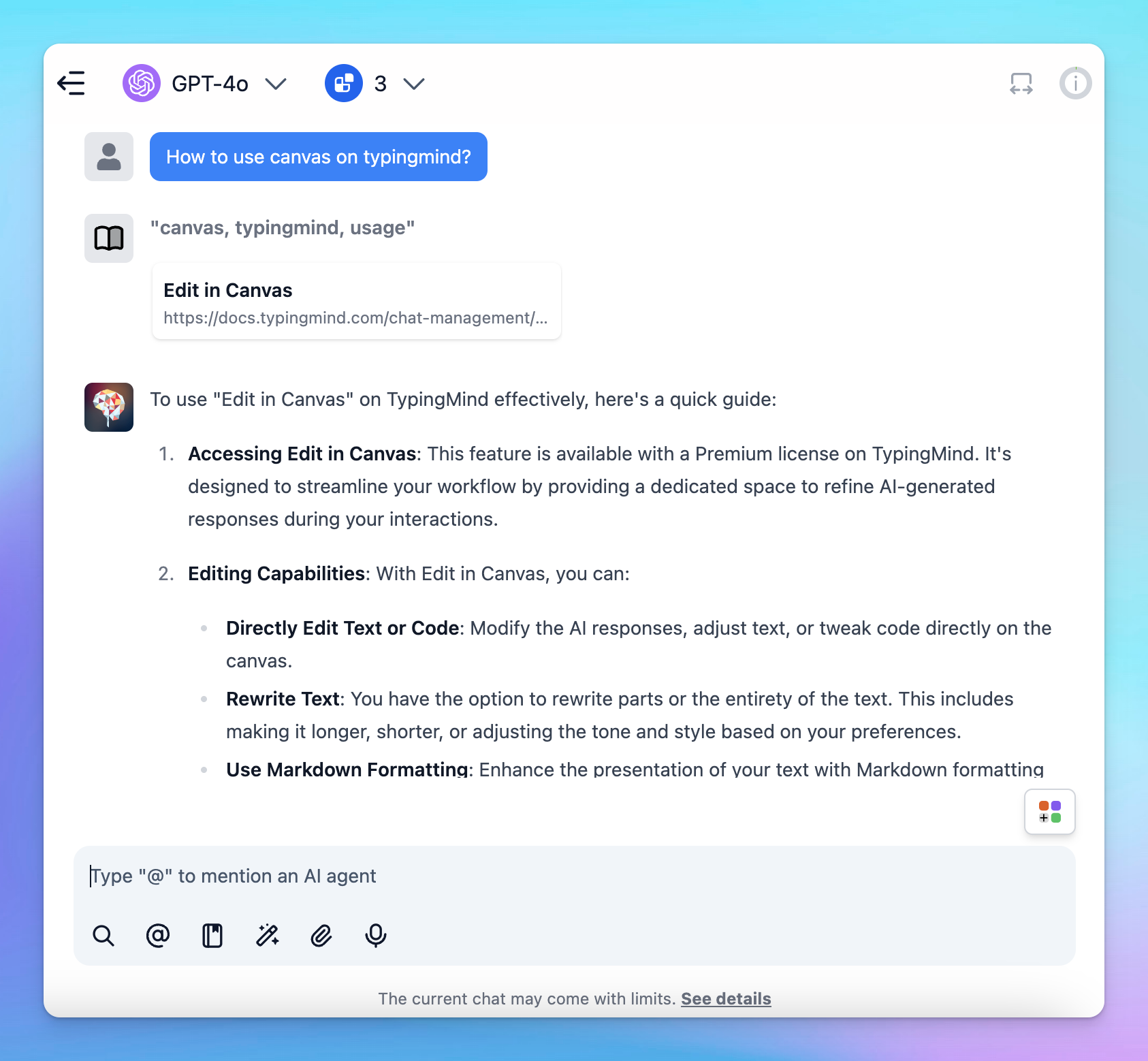
4. Connect knowledge base to AI Agent
Assign tags to your connect data so AI Agents can use it effectively.
Tags let you control which parts of the Knowledge Base the AI can access, making it more flexible and powerful.
Learn more: Connect knowledge base to AI Agent
Get started with Knowledge base
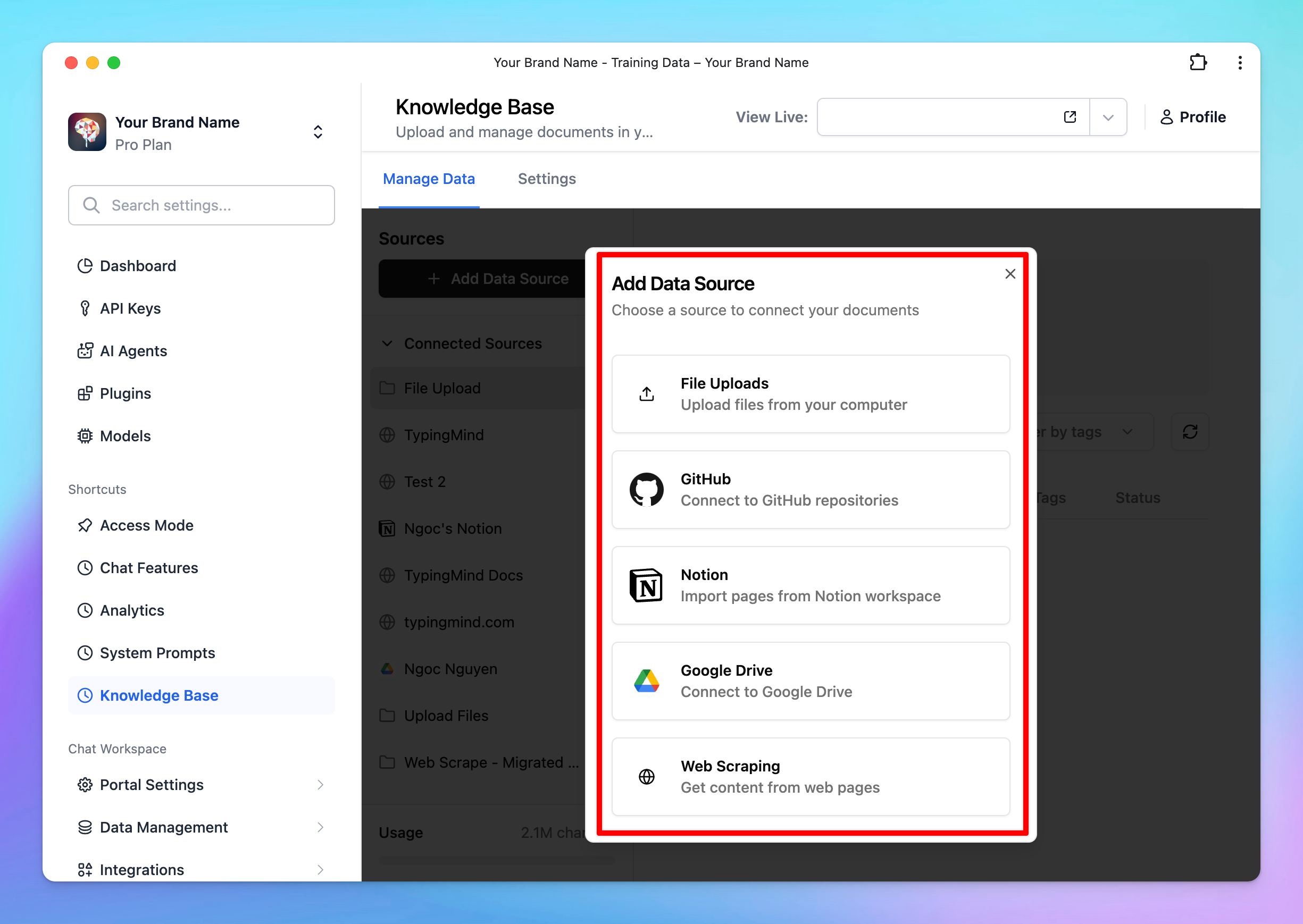
- Go to the Knowledge Base section under Data Management.
- Click Add Data Sources and select a source.
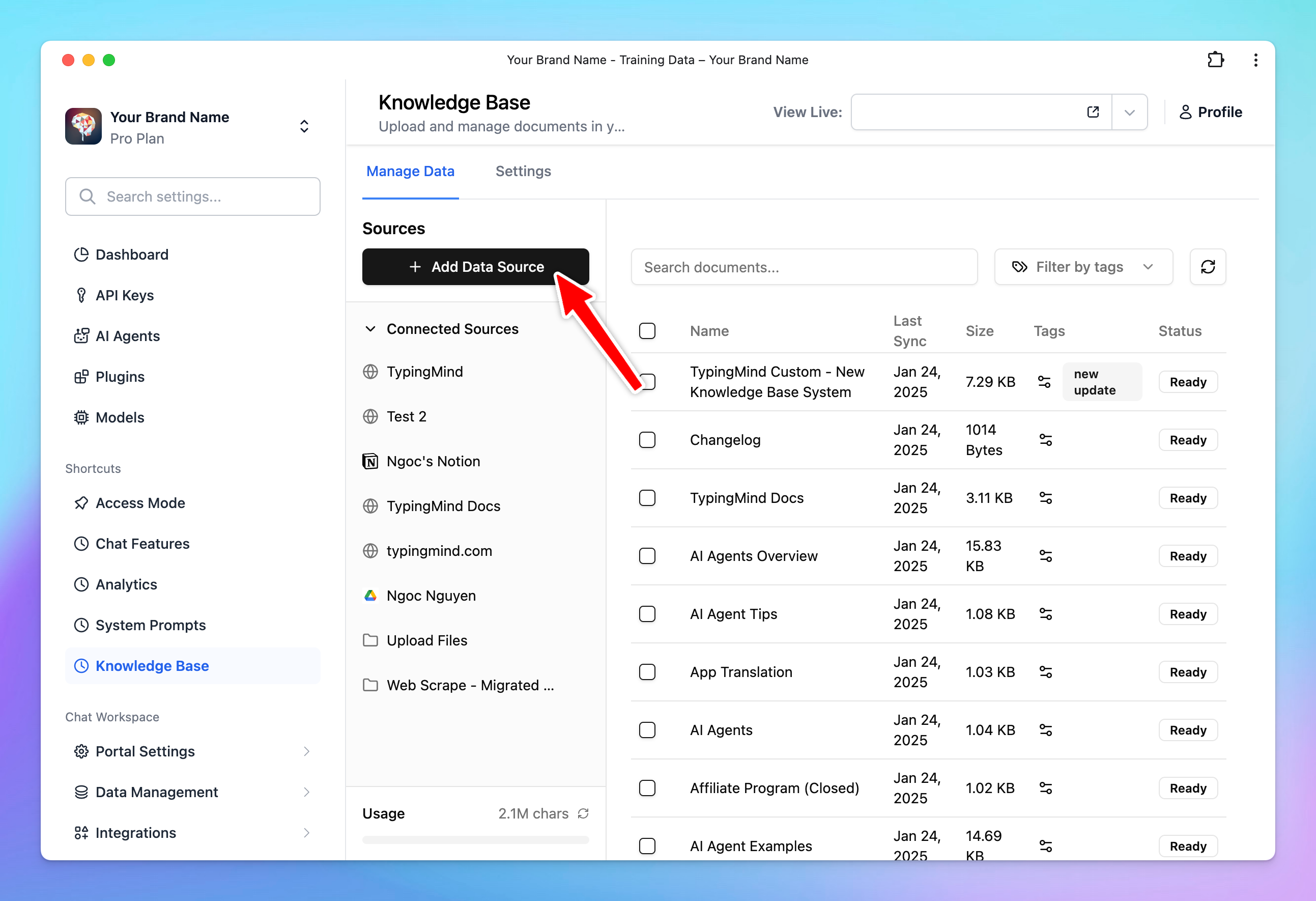
- Follow the steps in the app to connect your data.
- Each source is stored in a folder. To update a connection, click the folder and select Configure.
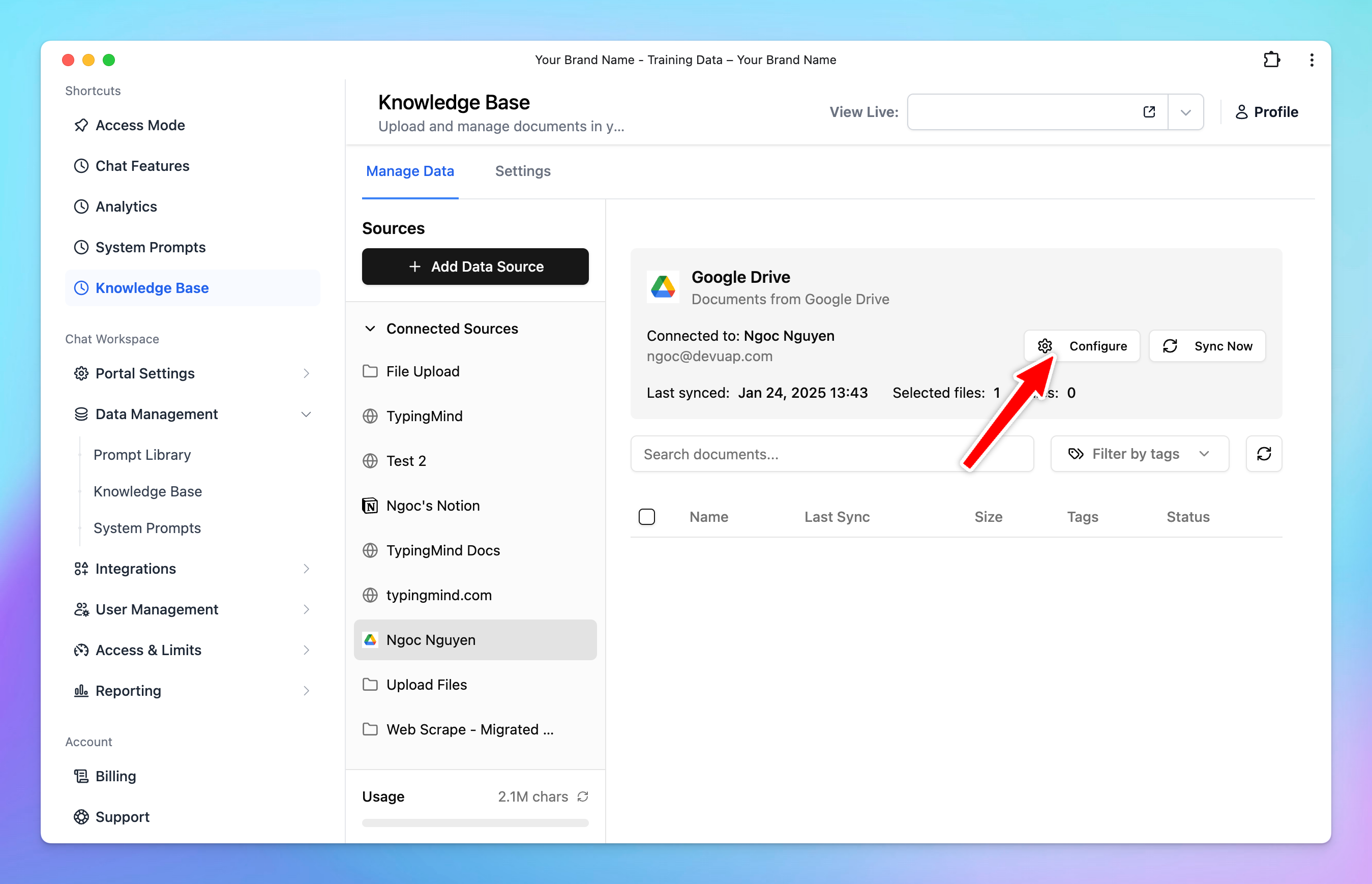
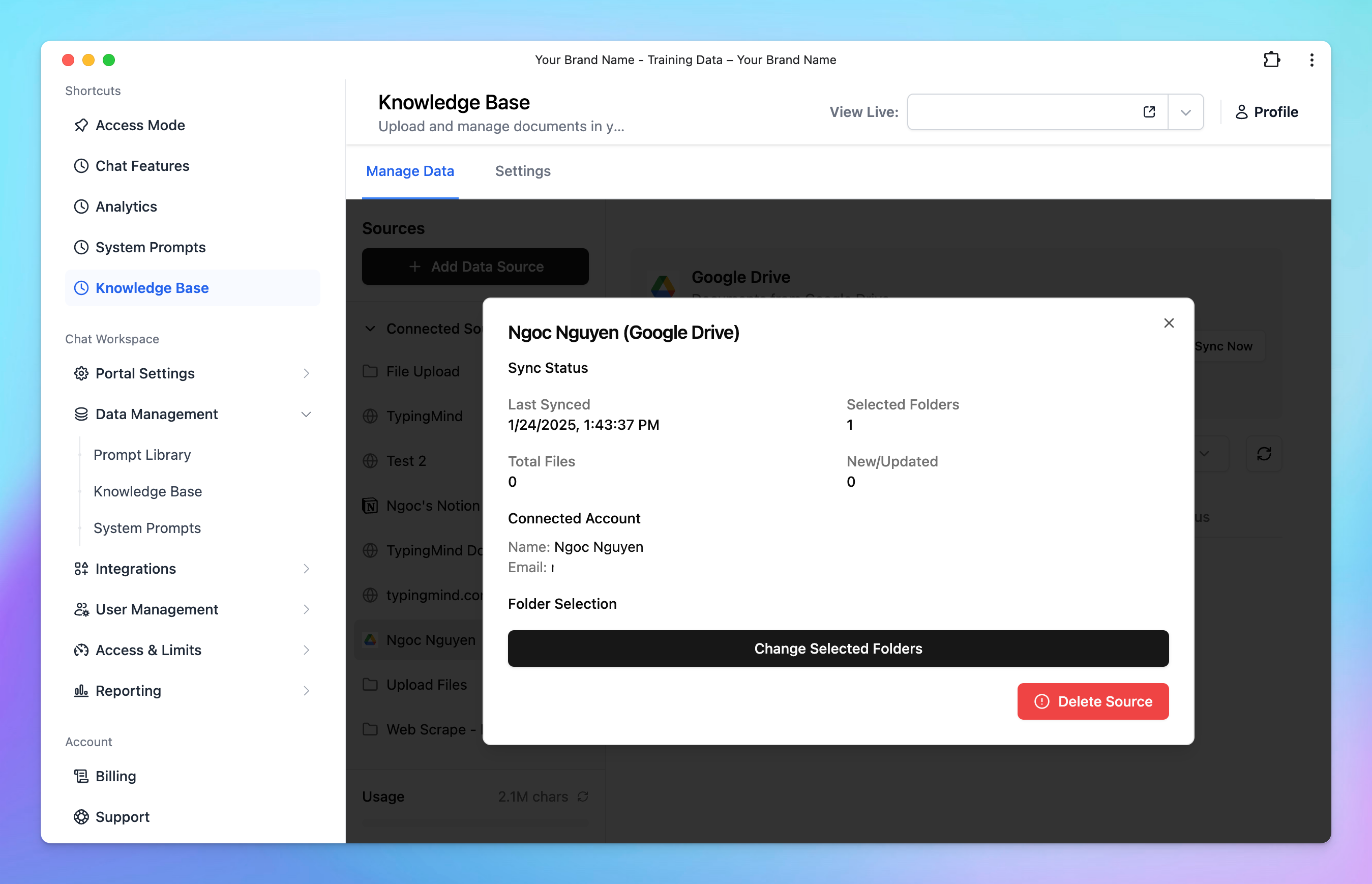
Available Sources for Knowledge Base
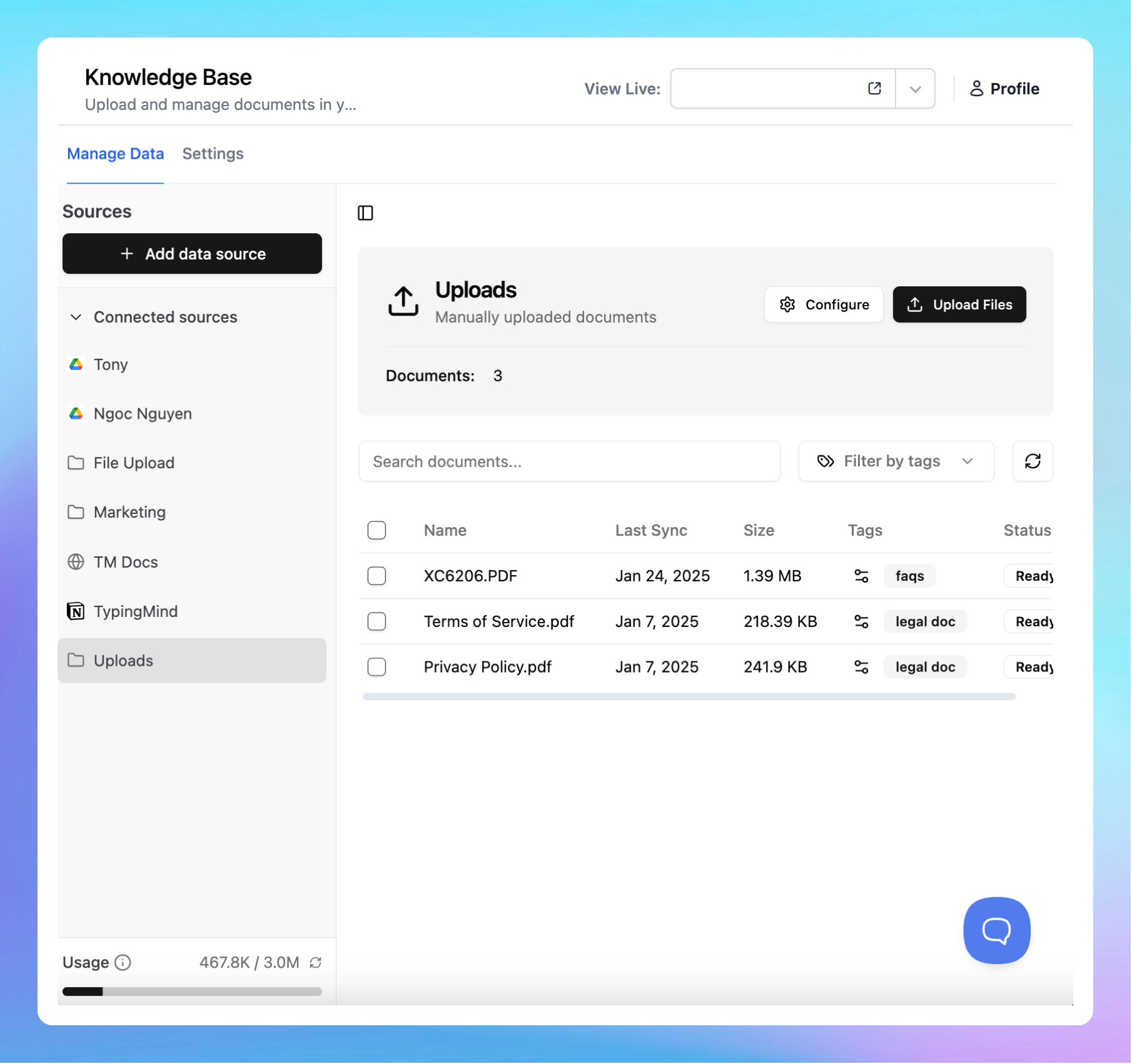
1. Directly upload your files
You can easily upload internal files as the app supports a wide range of file types, including PDF, DOCX, TXT, CSV, XLSX, and more. You can upload multiple files at once to centralize your data and make it accessible for training AI models.
2. Connect with your existing internal systems
Seamlessly pull data from various services you already use, such as Notion, Google Drive, Confluence, GitHub, Web Scraping, and more.
This allows you to integrate the data from these systems to train your AI assistant, thus ensuring your knowledge base is rich, comprehensive, and up-to-date.
How knowledge base works on TypingMind
The AI assistant gets the data from uploaded files via a vector database. Here is how the files are processed:
- Files are uploaded.
- We extract the raw text from the files and try our best to preserve the meaningful context of the file.
- We split the text into chunks of roughly 3,000 words per chunk with some overlap. The chunks are separated and split in a way that preserves the meaningful context of the document. (Note that the chunk size may change in the future, as of now, you can’t change this number).
- These chunks are stored in a database.
- When your users send a chat message, the system will try to retrieve 5 relevant chunks from the database (based on the content of the chat so far) and provide that as a context to the AI assistant via the system message. This means the AI assistant will have access to 5 most relevant chunks of uploaded data at all time during a chat.
- The “relevantness” of the chunks is decided by our system and we are improving this with every update of the system.
- The AI assistant will rely on the provided text chunks from the system message to provide the best answer to the user.
All of your uploaded files are stored securely on our system. We never share your data to anyone else without informing you beforehand.
Other methods to connect your knowledge base to TypingMind
Beside directly upload files or connect your knowledge base source via TypingMind, there are other options to connect your them to your chat instance:
- Set up System Prompt: a predefined input that guides and sets the context for how the AI, such as GPT-4, should respond.
- Implement RAG via a plugin: connect your database via a plugin (function calling) that allows the AI model to query and retrieve data in real time.
- Use Dynamic context via API for AI Agent: retrieve content from an API and inject it into the system prompt
- Use Custom model with RLHF method
More details on different levels of data integration on TypingMind: 4 Levels of Data Integration on TypingMind.
Best practices to provide knowledge base
- Use raw text in Markdown format if you can. LLM model understands markdown very well and can make sense of the content much more efficient compare to PDFs, DOCX, etc.
- Use both Knowledge Base and System Instruction. A combination of a well-prompted system instruction and a clean knowledge base is proven to have the best result for the end users.
- Stay tuned for quality updates from us. We improve the knowledge base processing and handling all the time. We’re working on some approaches that will guarantee to provide much better quality overall for the AI assistant to lookup your knowledge base. Be sure to check our updates at our Blog.
Be aware of Prompt Injection attacks
By default, all knowledge base are not visible to the end users .However, all LLM models are subject to Prompt Injection attacks. This means the user may be able to read some of your knowledge base.
